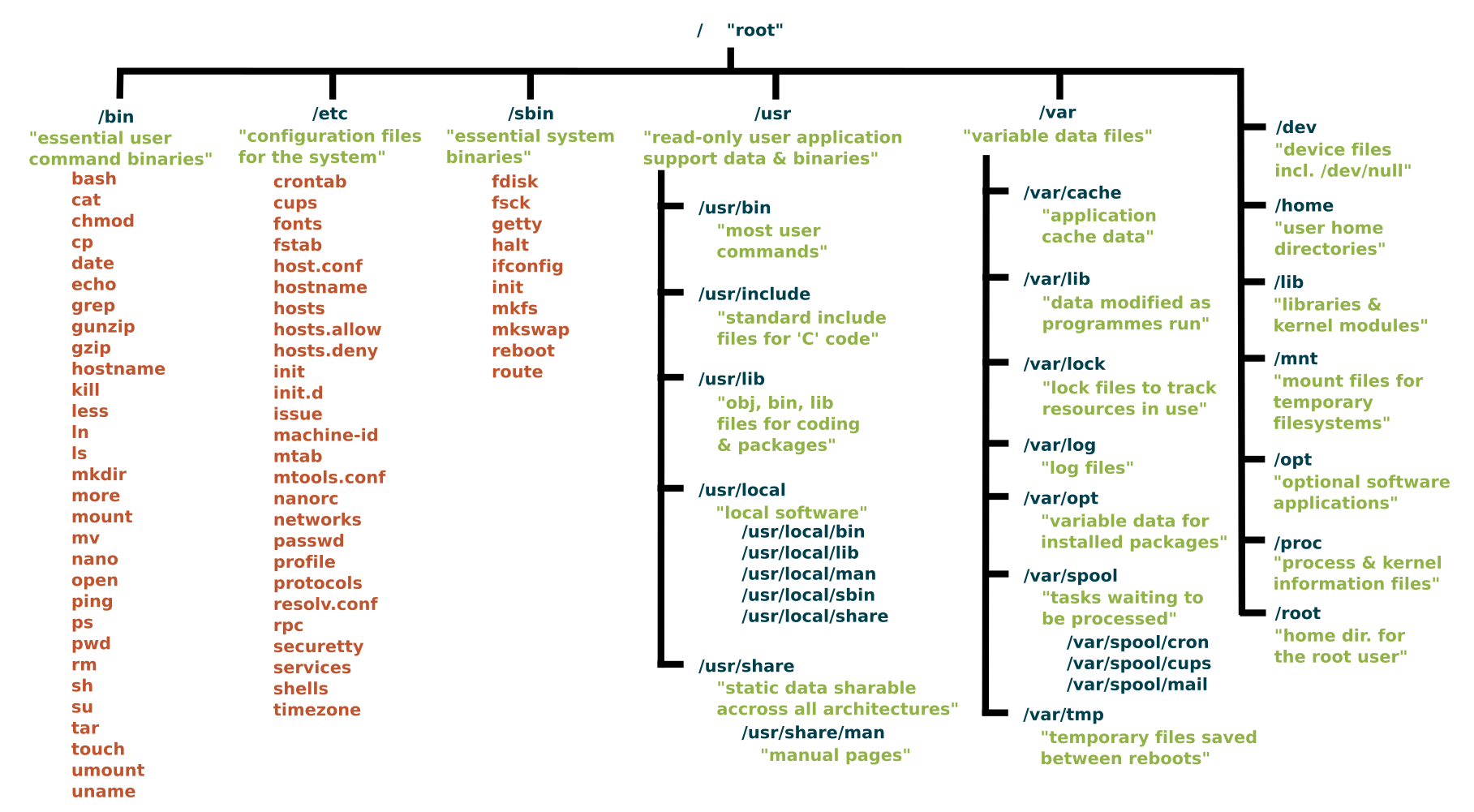
Molti filesystem UNIX hanno una struttura generale simile, anche se è possibile riscontrare delle differenze in alcuni dettagli. I concetti centrali di un filesystem Unix-like sono:
-
il reserved boot block: di default, in fase di creazione di un nuovo filesystem, il sistema si riserva un 5% di spazio, che può tornare utile nei casi in cui il filesystem fosse saturo, tanto da rendere difficili le operazioni di scrittura, anche da parte di processi privilegiati, quali i demoni di sistema, oppure tanto da rendere necessario un buffer, nei casi in cui l’allocatore di blocchi avesse seri problemi a trovare blocchi contigui o vicini, al fine di evitare eccessivi problemi di frammentazione. Per sapere quanto spazio è stato assegnato al reserved boot block, eseguire il comando:
dumpe2fs /dev/sda1 | grep Reserved
che legge il contenuto del superblock del file system.
-
il superblock, allocato nel blocco di dati 1, è un’area del filesystem che contiene le informazioni sull’intero filesystem, comprese le sue dimensioni, il numero di blocchi, le dimensioni dei blocchi, ecc. Per ovvie ragioni di sicurezza, il superblock viene duplicato più volte, all’interno del filesystem. Se il superblock di un file system fosse corrotto, potrebbe rivelarsi impossibile montare quel file system.
-
Il comando:
dumpe2fs
estrae, dal superblock e dai gruppi di blocchi, le informazioni relative ai filesystem ext2, ext3 e ext4. Un file system ext4 viene diviso in una serie di gruppi di blocchi, per tentare di ridurre il fenomeno della frammentazione dei file. L’allocatore dei blocchi tenterà sempre, per quanto possibile, di mantenere i blocchi dati di uno stesso file all’interno dello stesso gruppo di blocchi, così da ridurre i tempi di ricerca. Il numero dei blocchi per ciascun gruppo è prestabilito e non può essere modificato. Ciascun gruppo di blocchi contiene una mappatura a bit (bitmap) degli inode presenti nel gruppo e una mappatura a bit dei blocchi dei dati. In una mappatura a bit (bitmap), un bit impostato a 1 identifica un oggetto non disponibile, mentre un bit non impostato (0) indica un oggetto non utilizzato, quindi disponibile. Quindi, per entrambe le tabelle bitmap, un bit rappresenta una specifica zona di dati o uno specifico inode. Ciascuna di queste tabelle occupa un blocco di dati. Con le dimensioni dei blocchi a 4 KB (4096 byte), ciascun gruppo di blocchi conterrà 32.768 blocchi, per una lunghezza di 128 MB, poichè 4096 byte corrispondono a 32.768 bit e ad ogni bit della tabella bitmap corrisponde un blocco di dati. Stesso discorso per gli inode: ciascun gruppo di blocchi potrà contenere 32.768 inode. Le tabelle inode dei gruppi di blocchi occupano, tutte, lo stesso numero di blocchi. Se per ogni gruppo di blocchi possono esserci 32.768 inode, se ciascun inode occupa 128 byte, la tabella degli inode avrà un dimensione di 4.194.304 byte, che possono essere contenuti in 1024 blocchi da 4096 byte ciascuno. Un blocco è, a sua volta, un gruppo di settori del disco, compresi tra 512 byte e 64 KB. Il numero dei settori deve essere una potenza di 2. Ogni gruppo di blocchi, oltre alla tabella degli inode, ha un descrittore del gruppo. Un descrittore di un gruppo di blocchi contiene le meta informazioni su un particolare gruppo di blocchi: l’intervallo (range) dei numeri inode presenti nel gruppo, i blocchi presenti nel gruppo, l’offset dei blocchi chiave del gruppo. In un filesystem ext4, i campi sono scritti in ordine little-endian, mentre i campi in jbd2 (il journal) sono scritti in ordine big-endian. Questo significa che, se l’identificativo della partizione (Filesystem UUID) fosse la sequenza:
fafbb9fc-1565-4d53-9c75-ccfd2b2edeba
eseguendo un comando
dd, per leggere direttamente dal disco fisso, troveremmo la sequenza modificata, con il byte meno significativo di ogni coppia di byte posto prima del byte più significativo (little-endian order):
fbfa fcb9 6515 534d 759c fdcc 2e2b bade
La copia primaria del superblock risiede nel primo gruppo di blocchi ed è il superblock che viene letto dal sistema quando monta il file system. Visto che i gruppi di blocchi vengono contati da zero, possiamo dire che il superblock primario si trova all’inizio del gruppo di blocchi 0. Le copie di backup del superblock si trovano solo nei gruppi di blocchi 1 e quelli espressi da potenze di 3, 5, 7.
Il comando:
dumpe2fs -h device
dumpe2fs -h /dev/sda1
estrae solo i dati contenuti nel superblock, omettendo i dettagli contenuti nei descrittori dei gruppi di file.
-
gli inode (Index Node). Un inode è una struttura di dati, composta da campi di 128 byte ( nella forma estesa, 256 byte ), che contiene le informazioni (metadata) relative ad un oggetto presente nel filesystem (file o directory). Tutti gli inode sono conservati in una tabella, la tabella degli inode. In un filesystem Linux/Unix, gli inode occupano solo l’1% dello spazio disco disponibile, sia che si tratti dell’intero disco fisso, sia che si tratti solo di una partizione di esso. La tabella degli i-node viene memorizzata nei blocchi successivi al blocco 1 di un disco logico (disco o partizione), a partire, quindi, dal secondo blocco. La tabella degli inode è ordinata numericamente: il primo record è il record 1, l’ultimo record è numerato con il numero n, che rappresenta il numero massimo di file (meno uno, per essere precisi) che il file system può tenere. I numeri usati per indicizzare la tabella degli inode vengono chiamati I-number. Lo I-number 1 non è utilizzato: il suo spazio (128 o 256 byte) viene a volte usato per conservare le informazioni sui cosiddetti bad sector del disco. Lo I-number 2 è riservato all’inode della directory radice (root) del file system. I blocchi del file system riservati ai dati veri e propri (cioè, ai file) partono subito dopo la tabella degli inode. Ciascun inode, un record della tabella degli inode, contiene le informazioni relative ad un singolo file. Ogni volta in cui viene creato un nuovo file, all’interno di una directory, il sistema assegna al nuovo file un nome ed un numero di Inode. Quando un utente desidera aprire un file, utilizza il nome del file per indicarlo, ma, internamente, quel nome di file deve essere tradotto nel suo corrispondente numero Inode. Nell’inode di un file non viene conservato il nome del file. Il nome di un file viene conservato solo nella directory di appartenenza. Una directory è una semplice tabella che contiene i nomi dei file e i numeri di inode corrispondenti. I primi due record di questa tabella sono sempre:
.
..
Il primo punta all’inode della directory corrente, mentre il secondo punta all’inode della directory parent. Una volta ottenuto il numero di Inode associato al file, l’inode del file viene recuperato. Anche se i filesystem e le funzioni che gestiscono gli inode possono differenziarsi tra loro, tutti devono mettere a disposizione almeno i seguenti attributi di un file:
-
il numero di inode;
-
Device ID ( lo ID della periferica sulla quale il file è memorizzato );
-
i puntatori ai blocchi del disco contenenti il file. Un inode può contenere i puntatori a pochi blocchi. Se i blocchi contenenti il file fossero di più, il filesystem allocherebbe dinamicamente uno spazio addizionale per i puntatori necessari. Questi blocchi allocati dinamicamente vengono chiamati indirect block, poichè, prima di arrivare al blocco di dati del file, occorre arrivare a questo spazio addizionale allocato. Più precisamente:
-
i primi 10 indirizzi puntano direttamente a blocchi di dati (indirizzamento diretto). Quindi, 10 blocchi di dati sono accessibili direttamente.
-
l’undicesimo indirizzo punta ad un blocco contenente, a sua volta, indirizzi a blocchi di dati (indirect block a indirettezza singola). Se la dimensione del blocco di dati è di 512 Byte, se un indirizzo è composto da 32 bit (4 byte), il numero di indirizzi contenuti in un solo blocco è 128. Quindi, utilizzando questo undicesimo indirizzo ed il blocco al quale punta, con i suoi 128 indirizzi, è possibile indirizzare fino a 64 KB (65536 bit) di spazio (128 * 512).
-
il dodicesimo indirizzo punta ad un blocco di dati che contiene, a sua volta, altri 128 puntatori, ciascuno dei quali punta, a sua volta, non ai blocchi di dati, bensì ad un secondo blocco, che contiene altri 128 puntatori, che puntano, finalmente, ai blocchi di dati (indirettezza doppia). In questo caso, è possibile indirizzare fino a 8 MB (8.388.608 bit) di spazio (128 * 128 * 512).
-
il tredicesimo indirizzo, infine, punta ad un blocco di dati, contenente altri 128 indirizzi, ciascuno dei quali punta, non ai dati, bensi ad un altro blocco di altri 128 puntatori, ciascuno dei quali punta, ancora, ad un terzo blocco di altri 128 puntatori, che, a loro volta puntano ai dati. In questo caso, è possibile indirizzare fino a 1 GB (1.073.741.824 bit) di spazio (128 * 128 * 128 * 512).
Quindi, la dimensione massima di un file può essere di 1GB+8MB+64KB+5KB. Nei file system moderni, è possibile trovare 15 indirizzi (puntatori), all’interno dell’inode.
-
-
il tipo di file. Nei sistemi Linux, esistono più tipi di file:
-
Regular file
-
Directory
-
Link simbolici
-
Pipe e named pipe ( chiamati anche FIFO, First In, First Out ). Un pipe è un meccanismo che permette di inviare l’output di un programma ad un secondo programma, come input. Solitamente, i pipe sono anonimi ( unnamed ). Un named pipe è un meccanismo identico, che, però, si serve di un file, al contrario di un pipe unnamed, che risiede direttamente in memoria.
-
Socket: mette in comunicazione due processi, anche se residenti su macchine diverse.
-
Block-oriented device file ( i file a blocchi di periferica ). Un esempio è il disco fisso. Il driver di periferica legge interi blocchi di dati inviati, un blocco dopo l’altro, servendosi di un buffer ( area di memoria temporanea ). L’utente potrà accedere ad uno qualsiasi dei byte contenuti in un blocco, senza dover rispettare alcuna sequenza preordinata ( accesso casuale ).
-
Character-oriented device file ( i file a caratteri di periferica ). Un esempio è la tastiera del computer, che invia un carattere alla volta ( scrittura e lettura sequenziale, non casuale o randomizzata ). Il driver di periferica, in questo caso, leggerà la sequenza dei byte inviati, nello stesso ordine in cui sono stati inviati ( accesso sequenziale ), senza la necessità di utilizzare un buffer di memoria.
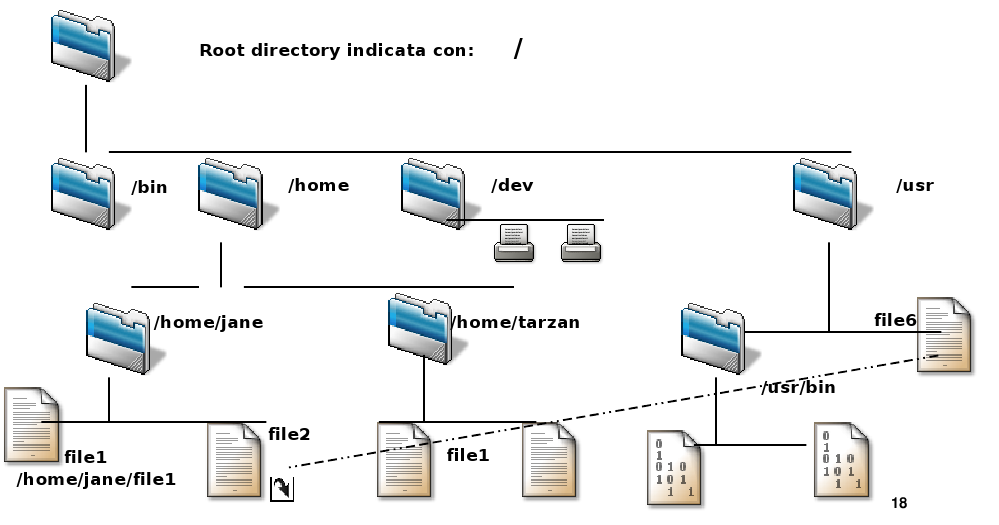
I file di periferica, a caratteri o a blocchi, si trovano nella cartella:
/dev
mentre una lista di driver per periferiche, a caratteri o a blocchi, attualmente caricati in memoria, si trova nel file:
/proc/devices
In questo file, troviamo, per ciascuna periferica il cui driver sia stato caricato in memoria, sia il nome, sia il cosiddetto Major Number.
Character devices:
1 mem
4 /dev/vc/0
4 tty
4 ttyS
5 /dev/tty
5 /dev/console
5 /dev/ptmxBlock devices:
1 ramdisk
3 ide0
9 md
22 ide1
253 device-mapper
254 mdpIl Major Number identifica il driver da utilizzare per accedere alla periferica. Ciascuna periferica deve essere supportata dal suo specifico driver. Per esempio:
/dev/null
/dev/zero
sono gestiti entrambi dal driver 1, mentre i terminali:
/dev/tty
/dev/tty0
/dev/tty1
sono gestiti dal driver 4. Un driver altro non è che un insieme di funzioni ( routine ) che, quando eseguite, permettono l’accesso ad una determinata periferica. Alcune di queste funzioni possono essere utilizzate da più periferiche dello stesso tipo: il disco fisso primario, per esempio, richiederà le stesse funzioni di accesso usate per un disco fisso secondario. Stessa cosa si può dire per ciascuna partizione di un disco:
ls -l /dev…
brw-rw—- 1 root disk 8, 0 2012-07-12 12:42 sda
brw-rw—- 1 root disk 8, 1 2012-07-12 12:42 sda1
brw-rw—- 1 root disk 8, 2 2012-07-12 12:42 sda2
brw-rw—- 1 root disk 8, 3 2012-07-12 12:42 sda3
brw-rw—- 1 root disk 8, 4 2012-07-12 12:42 sda4
… -
-
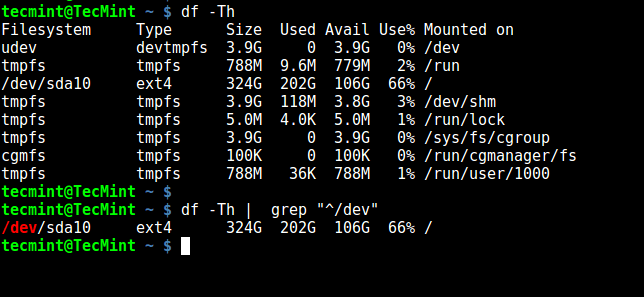
Questo è l’output del comando ls ( list ), eseguito all’interno della directory
/dev, dove vengono pubblicati il Major Number ed il Minor Number di ciascuna periferica ( device ). In questo esempio, abbiamo il disco “sda”, suddiviso in 4 partizioni. Il driver di periferica è contrassegnato dal numero 8 ( Major Number ). Per poter accedere ad una specifica periferica, però, per esempio alla partizione 2 di un disco fisso, è necessario specificare al kernel anche la periferica esatta. Questa è la funzione del Minor Number, nel nostro esempio: 0, 1, 2, 3, 4, che altro non è che un indice che punta ad un array locale di periferiche. Il numero 8 è il Major Number per tutti i dischi SCSI. -
i permessi associati al file. In un sistema Linux, un file non può essere utilizzato da chiunque. Per ciascun file, qualcuno ( il sistema operativo, l’amministratore, il proprietario del file ) stabilisce chi e cosa possa fare con un file. Un utente, rispetto ad un file, può rappresentare:
-
il proprietario ( owner ). Quando un processo crea un nuovo file, il file viene assegnato allo User ID del processo ( che rappresenta l’utente che ha lanciato il processo ), che ne diventa proprietario. Its owner user group ID can be either the process group ID of the creator process
-
il membro di un gruppo di utenti a cui il file è associato, proprietario escluso. Normalmente, quando un processo crea un nuovo file, il file viene assegnato al gruppo principale associato allo User ID del processo ( che rappresenta l’utente che ha lanciato il processo ).
-
un utente qualsiasi ( Others )
A ciascuna di queste tre tipologie di utente potranno essere assegnati o esclusi tre differenti permessi su ciascuno dei file presenti sul disco fisso:
-
Read (
r): l’utente potrà solo aprire il file in lettura, senza potervi apportare alcuna modifica. -
Write (
w): l’utente potrà aprire il file sia in lettura che in scrittura, con la facoltà di apportarvi modifiche. -
Execute (
x): l’utente potrà eseguire il file ( utile solo nei file eseguibili ).
Il listato del comando:
ls -l
restituisce, per ciascuno dei file elencati, i permessi assegnati, oltre al nome dell’utente proprietario e del gruppo ad esso associato:
-rwsr-xr-x 1 root root 36832 set 13 00:29 /bin/su
In questo esempio, vediamo che il file
su, presente nella directorybin, appartiene all’amministratore del sistema ( root ) ed è stato assegnato ad un gruppo chiamato, anch’esso, ” root “. Il gruppo di bit che rappresenta i permessi associati al file vengono stampati all’inizio:
-rwsr-xr-x
dove il primo bit:
-
non rappresenta un permesso, bensì il tipo di file, e può assumere i seguenti valori:
- ( regular file )
d ( directory )
l ( link simbolico )
s ( socket )
p ( named pipe )
c ( character device file )
b ( block device file )
mentre gli altri nove bit rappresentano i permessi assegnati al proprietario ( i primi tre bit ):
rws
ai membri del gruppo ” root ” ( i tre bit successivi ):
r-x
ed al mondo intero ( gli ultimi tre bit ):
r-x
Il mondo intero ed i membri del gruppo ” root ” possono leggere ed eseguire il file, ma non possono modificarlo. Il proprietario, invece, può leggere, sovrascrivere ( modificare ) ed eseguire il file, ma il terzo bit, dove appare la lettera s, segnala che il file
suha il bit SetUID impostato. Quando un file ha impostato il bit SetUID, è possibile eseguire il file con i privilegi del proprietario del file ( Effective User ID, EUID ), solitamente l’amministratore del sistema, o ” root “, che vanno ad integrare i privilegi assegnati all’utente che esegue il file. Questa estensione dei privilegi permette ad un utente diverso da ” root ” di accedere a file e directory ai quali, normalmente, non ha accesso. La lettera s impostata tra i permessi del proprietario del file, quindi, indica la volontà del proprietario di estendere i propri privilegi agli utenti che dovessero eseguire il file. La lettera s impostata tra i permessi del gruppo associato al file, invece, indica la volontà del gruppo associato al file di estendere i propri privilegi agli utenti di altri gruppi che dovessero eseguire il file:
-r-x--s--x
In questo caso avremo un GID ( Group ID ), che corrisponderà al GID dell’utente che esegue il file, ed un EGID ( Effective Group ID ) che corrisponderà al gruppo associato al file in esecuzione. Naturalmente, affinchè il SetUID bit o il setGID bit abbiano effetto è necessario che l’utente che tenta di eseguire il file abbia, su quel file, un permesso di esecuzione. Nel nostro esempio, chiunque ha il permesso di esecuzione, poichè tale permesso è compreso tra i privilegi del mondo intero ( Other ). Esiste anche la possibilità che il proprietario del file non abbia il permesso di esecuzione sul file stesso. In questo caso, il bit setUID verrebbe indicato con una lettera s maiuscola:
-r-S--x--x
Occorre ricordare che l’utilizzo del SetUID bit e/o del SetGID bit è da ritenersi una pratica alquanto pericolosa, poichè può autorizzare un utente ad effettuare operazioni sul filesystem che, in condizioni normali, non potrebbe effettuare. Questo è tanto vero, che i kernel di molti sistemi operativi Linux, oggi, ignorano totalmente il SetUID bit e il SetGID bit, quando applicati ad uno script di shell, accettandoli esclusivamente se applicati a file eseguibili già compilati ( binari ). Quando fosse indispensabile delegare le credenziali di amministratore ( root ) ad un utente terzo, sarebbe preferibile l’uso di uno dei due comandi:
su
sudo
SetUID bit, SetGID bit e Sticky bit ( un bit utilizzato per l’accesso alle directory, come vedremo più tardi ) sono permessi speciali che indicano la modalità in cui un file eseguibile dovrà essere eseguito. Per i permessi sui file, quindi, sono disponibili 12 bit.
000 000 000 000
Il primo gruppo di tre bit è dedicato ai permessi speciali. Il secondo gruppo di tre bit è dedicato ai permessi riservati al proprietario del file. Il terzo gruppo di tre bit è dedicato ai permessi riservati ai membri del gruppo proprietario del file. Il quarto gruppo di tre bit è dedicato ai permessi riservati al resto del mondo. I tre bit dei gruppi secondo, terzo e quarto, rappresentano, rispettivamente, il permesso di lettura ( r ), di scrittura ( w ) e di esecuzione ( x ). Quindi, un sequenza di bit del tipo:
000 111 101 000
indica che il proprietario del file ha tutti e tre i permessi attivi ( lettura, scrittura ed esecuzione ), i membri del gruppo proprietario del file hanno attivati i soli permessi di lettura e di esecuzione, mentre il resto del mondo non ha alcun permesso sul file. La notazione numerica di questa sequenza di permessi è:
0750
mentre la notazione alfabetica è:
---rwxr-x---
Come abbiamo appena visto, però, i permessi speciali vengono segnalati modificando il permesso di esecuzione per il proprietario del file ( SetUID ), oppure per il gruppo principale associato al proprietario del file ( SetGID ), oppure per il resto del mondo ( Other ) per lo Sticky bit.
-
-
lo UserID ( UID ) del proprietario;
-
il GroupID ( GID ) del gruppo principale del proprietario;
-
le dimensioni del file, in byte;
-
tempi di accesso e di modifica del file;
-
tempi di cancellazione del file;
-
il numero di hard link associati al file;
-
gli attributi estesi;
-
Access Control List ( ACL ).
Per ogni file presente nel filesystem, esiste un inode, nel quale il kernel cerca le informazioni di cui necessita. La sola informazione che un inode non contiene è il nome del file. Questo accade perchè un file, nel mondo di Linux, è rappresentato unicamente dal numero inode, mentre il nome non è altro che una etichetta ( label ), associata ad un inode. Più nomi di file possono essere associati ad uno stesso inode: questo significa che ciascun nome punta allo stesso inode. Per leggere i numeri inode dei file, eseguire:
ls -i
oppure:
stat [nome file]
Per leggere i numeri inode dele partizioni, eseguire:
df -i
-
-
la directory. La corrispondenza tra un nome di file ed il suo numero di inode è conservata in una struttura hash ( un elenco di coppie di dati: nome/valore ), chiamata Directory. Per ciascuna Directory, Linux crea un inode. L’inode di una directory conterrà, quindi, anche i permessi associati alla directory. I permessi associati ad una directory possono avere un significato differente dai permessi associati ad un file:
-
per creare, rinominare o eliminare un file, è necessario ottenere i permessi in scrittura per la directory che contiene il file. Questa è una caratteristica che spesso lascia perplesso chi si accosta per la prima volta ad un sistema Unix-like, dato che sarebbe intuitivo associare la cancellazione di un file al permesso di scrittura sul file. In realtà, la cancellazione di un file consiste solo nella rimozione di un riferimento da un hash chiamato directory. Il che comporta che per cancellare un file tutto quello che serve è il permesso di scrittura sulla directory che lo contiene, dato che è questa che viene modificata. I permessi sul file vengono completamente ignorati. Per le directory, inoltre, il permesso “write” permette di aggiungere nuovi link.
-
per modificare il contenuto di un file, invece, è necessario ottenere i permessi di scrittura per il file stesso, anche se non li si ottiene per la directory in cui il file è contenuto
-
per eseguire il comando
ls( che elenca i file presenti in una directory ), all’interno di una directory, è necessario ottenere i permessi di lettura ( read ) per la directory. Ipotizziamo di avere una directoryperlcon i seguenti permessi:
d-wx--x--x 2 myuser myuser 4096 2012-05-17 11:53 perl/
Senza il permesso “read” ( r ), è possibile spostarsi all’interno della directory:
cd perl
ma non è possibile eseguire il comando
ls, che restituirebbe un messaggio di errore:
ls: impossibile aprire la directory .: Permesso negato
mentre è possibile eseguire un comando
ls( o un qualsiasi altro comando, permesso dalle impostazioni di accesso abbinate al singolo file ) su uno dei file presenti, purchè se ne conosca il nome esatto:
ls -l find.sh-rw-r–r– 1 myuser myuser 26824 2012-05-08 13:57 find.sh
In questo modo, è possibile restringere l’accesso ad una directory ai soli utenti che ne conoscono, a priori, il contenuto.
-
Se, a questo punto, eliminassimo, per la cartella
perl, anche i permessi di esecuzione,x, sarebbe impossibile anche il solo accesso alla directory. I comandi:
cd perl
ls -l perl/find.sh
riceverebbero entrambi lo stesso messaggio di errore: “Permesso negato”. Il permesso di esecuzione, infatti, quando applicato ad una directory, regola l’accesso alla directory e a tutte le sottodirectory in essa contenute. Per questo motivo, il permesso di esecuzione, quando applicato ad una directory, viene chiamato “search bit” ed è presupposto necessario per l’accesso alla directory ed a tutte le sue sottodirectory.
-
Per le directory, il bit SetGID viene utilizzato per far sì che i nuovi file creati in una di esse abbiano come gruppo proprietario non quello del processo che li ha creati, ma quello del proprietario della directory stessa.
-
Per le directory, è possibile impostare un ulteriore permesso speciale, al pari dei bit SetUID e SetGID: lo Sticky bit, che indica che solo l’utente proprietario di un file o proprietario della directory che lo contiene oppure l’utente ” root ” ( amministratore di sistema ) potrà cancellarlo, anche se in presenza di un permesso di scrittura sul file, esteso a tutto il mondo ( Other ). Lo Sticky bit modifica la lettera che indica il permesso di esecuzione per tutto il mondo ( Other ) in una
t( che diventa unaTqualora il corrispondente permesso di esecuzione non sia attivo ):
drwxrwxrwt 8 root root 77824 Apr 22 16:47 tmp
All’interno di una directory, ciascuna coppia:
nomeFile inode
corrisponde ad un hard link, dove il nome
nomeFilepunta al file rappresentato dainode. Quando si cancella un file, si elimina solo un record nella tabella di una specifica directory, ma non necessariamente il record presente nella tabella inode. Infatti, quel numero di inode potrebbe essere puntato da altri link presenti nel sistema. Un record della tabella inode viene eliminato solo quando, nel sistema, non esistono altri link che puntino a quell’inode. Come sapere se esistono altri link che puntano ad uno stesso inode? Mantenendo, all’interno dell’inode stesso, un campo che contenga il numero dei link, presenti nel sistema, che puntano a quel record della tabella inode. Un vero e proprio contatore. Quando si crea un nuovo link ad un inode, il contatore di quell’inode viene incrementato di uno; quando si elimina un file ( link ), il contatore dell’inode corrispondente a quel nome di file viene decrementato di uno; quando il contatore di un inode è a zero, Linux elimina il record relativo all’inode. E’ possibile creare hard link che puntino a file salvati in un filesystem differente dal filesystem corrente? No. Ciascun filesystem, infatti, ha una sua propria tabella degli inode. L’inode numero 143 del filesystem A non potrà mai riferirsi allo stesso file contenuto nel filesystem B, con numero inode 143. Per creare un link ad un file salvato su un filesystem differente dal filesystem corrente, Linux mette a disposizione un altro tipo di link: il link simbolico, o symlink. Un link simbolico è un file a tutti gli effetti. Un link simbolico si vede assegnato, dal sistema, un numero di inode suo proprio. Un link simbolico è un file con un contenuto reale. Il contenuto di un link simbolico è l’indirizzo del file al quale il link simbolico punta. Ovviamente, un link simbolico è meno trasparente di un hard link. Difficilmente il filesystem B sarà cosciente della relazione esistente tra un suo file ed un file salvato nel filesystem A. -
